Road to Continuous Integration
Introduction #
About a year ago, I had some doubts about Continuous Integration because of how I had seen it working and some of the challenges that this methodology presents, Thereby I wanted to take a better approach at it in my new company. This article will guide you through my journey to Continuous Integration. Let’s get started.
Continuous Integration (CI) is a software development practice that recommends integrating to a repository main branch at least once a day and preferably more than once. Every time a commit is made and pushed to the remote Source Code Repository, it is built, verified and scanned in a different environment from the one used by the developer’s daily work to provide fast, reliable feedback to the development team. Very much like in the diagram below
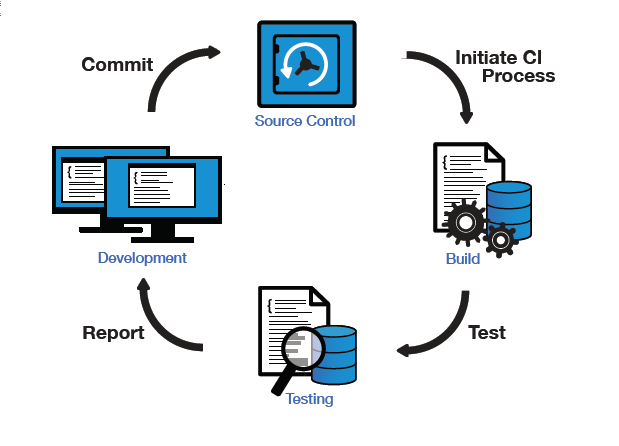
This relatively new approach allows the development team to detect and fix early bugs while developing, but this also presents a new set of challenges due to the fact that everyone is working on a single branch.
Benefits #
- Easier more often integrations => less Nº of conflicts to solve at once.
- Less testing surface for QA => the code only needs to be tested once.
- Increases testing visibility => generates shared responsibility for tests.
- Creates a (deployable) output artifact => reduces Time To Market (TTM).
- Catches bugs often and early => reduces the cost per bug found.
Challenges #
While all this sounds very appealing and beautiful when you read it, the reality is a bit hairier at the implementation time. For instance, having a remote server / job to build your code is very cool, but, what happens if you have 2 builds and you want them to run at the same time? This is where it all starts to get a bit messy and also, where we need Isolation.
Not to mention how to visualize when the build is broken and everyone has to stop working. It can honestly be a bit annoying to stop working because someone else broke the build, make sure to establish how to proceed in those cases. It also does not make sense to have every single person in the team looking at what happened, usually 1 to 3 developers looking into it is more than enough. We’re going to call this Visibility.
Another key aspect to the gig, is having a good set of tests that cover as much functionality as possible but without over testing everything and having one test per every single function (and believe me, that can happen if the wrong approach is taken, and if you obsess with the testing coverage). What I just described is the the cornerstone of this whole software development technique. We’re going to call this test Reliability.
Also imagine what could happen if you focus on testing a single implementation of the code but, over time you have to replace that implementation with something else that does the same i.e. changing Memcache for Redis, all the tests would have to be rewritten and that is a place where you don’t want to be. Abstract the specifics of the implementation and focus on testing the code functionality, not it’s nitty details. DDD for example, provides enough guidelines to organize the code appropriately.
Moreover, If you have a lot of tests, but they overlap or fail randomly, this means that your testing approach is not reliable enough, people will tend just ignore the Continuous Integration server status report and overtime, it will be just another failed attempt at doing this DevOps thing. Real case scenario of a conversation:
- John: Hey, I’m code reviewing task
ABC-1234, and I noticed that the CI build is red again, should we do something to fix it? - Sam: Well, it does that over time, plus, I spent a couple of days trying to reproduce why test
IfParameterIsFooShouldLogLineInFilefailed, but could not get it to happen retrying the build. - John: Ok then, I’ll just ignore the status and merge it to master.
So, as you rely more and more in automated tests, your test suite number can grow noticeably, and so can the execution time for those tests. It is extremely important that you have the ability to run some of them in parallel (even if you don’t need that feature straight away, it can be needed in the future) to keep that build time as fast as possible to have that feedback as soon as it can be provided. This is the Speed aspect.
Our Approach #

At my current company, we Continuously Integrate all the new components or services and currently moving or looking to move some of the legacy systems to this approach due to the amount of speed and reduced issues during the software development process. Before we went for it few options and technologies had to be considered.
As most of our codebase is private we needed to choose between 2 approaches:
- Self hosted Jenkins (already being used for other tasks).
- Use a hosted CI solution.
First, we explored the Jenkins approach, but to success in the attempt, we needed:
- An Amazon Machine Image (AMI) (or Docker Image) for every language and version we had for our stack.
- A Jenkins master orchestrating all the slaves receiving jobs.
That seems fairly feasible if you have 1 or 2 languages with a couple of versions in your software stack, but as it turns out, at the time I’m writing this article, we have far more than that:
- PHP 5.5, 5.6, 7.0
- NodeJS 4.3, 4.3
- Python 2.7
- Golang 1.6
That translates into 7 different AMIs to build, maintain and troubleshoot, then, not an option for us. Even if we looked at the Docker Image approach, we’d still have to maintain the Jenkins master / slave setup hosted in AWS which would easily exceed what we were willing to pay for that infrastructure and would create a lot of maintenance overhead. On the other hand, we wanted the CI platform to be easily customizable, and if possible, have the ability to integrate the definition of the build inside the same code repository that we would build.

We chose to stop exploring the Jenkins approach and instead, focus on a hosted CI solution that offered us enough customization, and a single file for the build declaration. After a couple of weeks playing with 3 or 4 of them, we decided to keep using CircleCI for our private builds, Here are some of the reasons:
- Extremely easy to parallelize builds.
- YAML build declaration format.
- $50 per concurrent build (container) and 1 free container.
- Tons of external services to use for your build like MySQL, Redis, Solr…
- Good Slack integration.
- Fast builds.
- Very good documentation around all the areas.
- Allows sudo access inside the container.
- Supports the languages we use (AND MORE!)
What we did not like:
- Some limitations around the Docker commands due to the LXC Driver being used.
- No travis-like multi-version build configuration.
- No visual CD pipeline available.
All in all, it’s been a huge win to integrate our Software development and delivery process with CircleCI. We’re not only doing CI but CD as well (more of that in a future post).

This enables every project to have a custom build and pipeline configuration without disrupting the other builds! I can say we achieved Isolation.
Here’s the YAML configuration for an ongoing project of mine. All the automation is Makefile and Docker centric. But you can see how easy it is to set up the whole build just by typing a few lines:
general:
artifacts:
- "dist" # Contains binaries
- "dist/junit" # Contains Junit
machine:
pre:
- sudo add-apt-repository -y ppa:masterminds/glide
- sudo apt-get update
- sudo apt-get install glide -y -qq
- curl -sSL https://s3.amazonaws.com/circle-downloads/install-circleci-docker.sh | bash -s -- 1.10.0
environment:
CRAFTER_ROOT: /home/ubuntu/${CIRCLE_PROJECT_REPONAME}
CRAFTER_GOPATH_ROOT: $HOME/.go_project/src/github.com/cmproductions/${CIRCLE_PROJECT_REPONAME}
GOPATH: ${GOPATH}:$HOME/.go_project/
services:
- docker
dependencies:
pre:
- ./ops/scripts/cleanupci.sh
override:
- mkdir -p $HOME/.go_project/src/github.com/cmproductions
- ln -fs ${CRAFTER_ROOT} ${CRAFTER_GOPATH_ROOT}
- cd ${CRAFTER_GOPATH_ROOT} && make deps
test:
override:
# Run all tests
- cd ${CRAFTER_GOPATH_ROOT} && make tests
post:
- mkdir -p ${CIRCLE_TEST_REPORTS}/junit/
- cp ${CRAFTER_GOPATH_ROOT}/dist/junit/* ${CIRCLE_TEST_REPORTS}/junit/
Ok, What about visibility?
We have the CircleCI integration set up both in GitHub (So it hooks to the GitHub API and reports the build result to every single commit) and Slack. It automatically sends a notification about any failed build to the relevant Slack channel. At all times, we know if a commit is healthy or not.
Moving on, What did we do to tackle test reliability?
First, we removed external dependencies like calls to 3rd party services, and mocked those to set them out of the equation. If the codebase was fairly new, created mocks inside the codebase to be able to test request and response matches. On the other hand, if the codebase was more leaning towards legacy, using services that act as an HTTP proxy / gateway, which provided an exact functionality with a bit more configuration overhead.
Libraries:
Mocking gateways:
[1]: Still moving towards this approach.
[2]: Tool created by one of our developers Jordi Martin.
Last, but not least, how did we keep the build time acceptable?
First, we divide our tests in a few suites, which at least are 2; unit and functional. There’s also projects that have a QA involved, who then adds the corresponding test suite inside the same code repository so that everything remains version controlled in GitHub. We still have not had to parallelize builds and spread them out in different containers, but that’s one of the next tests that should be taken into account to speed some things up.
Workflow #
To really get the most out of CI, there’s some changes that have to be made to adapt to this new way of using Source control, remember: instead of using branches to separate your changes from everyone else’s, you’ll now check out your changes in the same branch on which everyone is working to provide fast integrations which are much less painful than long ones.
To be able to do that, you might want to use techniques that allow that, such as feature toggles. That way even if your code is not yet finished, it will not mess up the build health or piss off your coworkers.
Another important thing to consider is blaming someone when they break the build, because that will make people reticent to write tests so that they don’t fail and that prevents anyone for getting blamed, instead, get into the we build and break the software as a team motto which will be much more effective and psychologically easier for all the involved parties.
This will:
- Maintain Effectivity
- Reduce the amount of failed builds
- Prevent bottlenecks
If for any reason you like to blame someone you could build something cool like this
The blog post behind building it here
Conclusion #
Summarizing, CI works and brings great value to software development teams that are willing to spend a considerable amount of time not only following the theoretic guidelines but also refining how they work and interact everyday with each other, some of the tips that we applied at our company and worked pretty well for us are:
- Do not do CI with legacy code (not very testable) without testing it out first on new codebases or codebases that are relatively small and align with the micro service approach.
- Create a pre-push git hook that prevents work from being pushed to the remote repository to prevent pushing work if the build is broken (remember everyone has to work on fixing it).
- Have a great test coverage that extensively tests your code, that can include breaking down your tests in different suites, like unit, functional and end-2-end.
- Parallelize tests when the build time is >10 minutes to speed up the feedback loop.
In the next post we will take a look at the next step, Continuous Delivery
If you liked this blog post, click on recommend below or follow me on Twitter